# Python 的编码问题 - 文件乱码的根源
# 缘起
编程时偶尔会遇到乱码问题, 虽然知道是因为编码不一致导致乱码, 但是一直没有头绪, 总是"头痛医头脚痛医脚", 碰到乱码了, 就上网查询别人的解决方案, 却一直没深入搞清楚乱码的原因.
# 1. 为什么需要"编码"?
大家应该都听说过传送电报使用的"摩斯电码(Morse Code)".
由于当时技术受限, 人们通过电键敲击出"点"、"划"以及中间的"停顿", 用于表示英文字母、数字和标点符号.
比如 SOS 的摩斯密码是 ···---···
之后, 人们通过编制"电码表", 用多个数字来指代某个字符, 这样就可以使用简陋的摩斯电码来表示各种语言字符.
比如, 1873年, 为了使用电报传递中文, 法国驻华人员威基杰参照《康熙字典》的部首排列方法,挑选 6800 多个常用汉字, 编成第一部汉字电码表 --《电报新书》.书中采用 4 位数字来指代一个汉字. 从 0001 到 9999 按顺序排列,表示了一万个汉字、字母和符号:

同样的, 计算机也会面临技术限制 -- 由于发明计算机时的技术限制, 人们选择"二进制"存储数据, 也就是说, 数据以 0 和 1 的形式存储在计算机中.
那么, 同样的, 人们也编制了"编码表"(就类似上面的"电码表"), 使用多个 0 和 1 来指代某个对应的字符. 这就是编码产生的原因.
# 2. 编码的历史问题
# 第 1 阶段
我们从前面得知, 由于技术限制, 人们制定了"编码表"来映射二进制和字符的关系.
而计算机和互联网是美国人发明的, 所以在设计计算机编码时, 只考虑了英文. 该编码表的名称是 ASCII (American Standard Code for Information Interchange), 使用 8 个 0 或者 1 的组合 (也就是8个比特, 也称为 1 个字节) 来表示 1 个英文字符.
但是, 其他国家也需要使用计算机, 不可能每个人都使用英语来操作计算机, 怎么办?
# 第 2 阶段
于是, 各个国家推出各自的编码表, 让本国人可以使用本国语言来使用计算机:
- 中国推出了 GB2312 编码表, 后期扩展成 GBK 编码表 (以支持更多字符)
- 日本推出了 Shift-JIS 编码表
- 韩国推出了 ks_c_5601-1987 编码表
- ...
这些编码表, 解决了"用本国语言使用计算机"的问题, 但是各个编码表之间是不兼容的. 也就意味着, 其他国家的文字在本国计算机上会显示乱码.
# 第 3 阶段
为了解决上面的不兼容问题, 人们设计出了 "Unicode / 万国码", 在一张表中对全球大部分的文字进行编码. 那么, 所有国家的计算机只要使用这张编码表就可以正确显示所有国家的文字了.
而且, Unicode 还记录了与各国原有编码表的映射关系. 比方说, Unicode 中不光编码了汉字, 还记录了所有汉字在 CJK 中的对应编码. 这就意味着, 即使字符串是 CJK 编码, 也可以使用 Unicode 来解码.
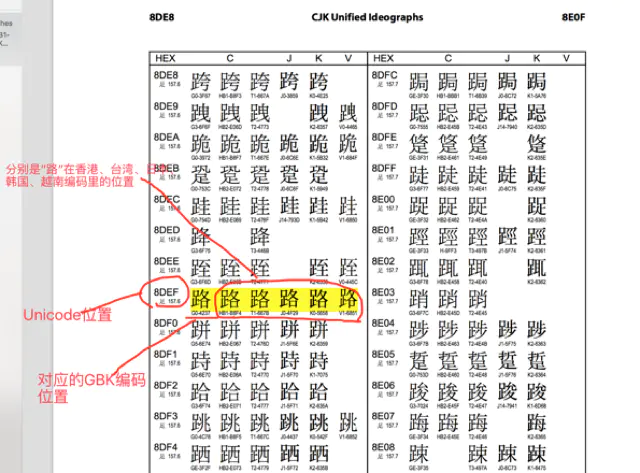
一切似乎都很完美, 但是, 由于 Unicode 需要涵盖地球上大部分的语言, 这导致它需要使用非常多的字节空间来表示某个语言的某个字符 (Unicode 使用 2-4 个字节来编码 1 个字符, 即 16-32 比特)
这造成的问题是, 原来使用 ASCII 编码的文件( 1 个字符只需要 8 个比特来表示), 如果使用 Unicode 来编码( 1 个字符需要用 16-24个比特来表示), 文件体积将增加了一倍多.
不过, 受益于技术发展, 现在的计算机内存比较大, 而同一时间处理的字符串容量并不会特别大(远小于内存), 所以, 在本地计算机的使用中, Unicode 带来的体积增大的问题丝毫不严重.
但是, 受限于技术水平, 现在的带宽资源还是相对稀缺的, 如果因为使用 Unicode 编码而导致网络传输增加 1 倍的体积将是无法容忍的!
我们在选购服务器时会发现, "增加带宽产生的费用"远远高于"增加硬盘空间产生的费用". 你可以在 阿里云服务器选购 (opens new window) 里面体验一下"带宽"的价值
# 第 4 阶段
于是, 人们又设计了 "UTF(Unicode Transformation Format)" 编码表来解决这个问题.
UTF 对 Unicode 进行转换, 并兼容 ASCII:
- 表示英文字符时, 采用和 ASCII 一样的编码 ( 8 个比特表示 1 个字符)
- 表示中文时, 使用原来 Unicode 编码 (一般情况下, 24 个比特表示 1 个字符)
最终, UTF 成为现阶段符合各方面需求的编码, 也因此被广泛使用. 同时, Unicode 作为万国码, 尤其是它记录了与各个编码表的映射关系, 因此会作为编码转换过程的中介来使用.
# 3. Python 中的编码问题
# Python 2
由于 Python 2 默认编码是 ASCII, 而中文版的 Windows 操作系统使用的是 GBK 编码, 所以 Python 程序中的汉字在 Windows 终端中会显示乱码.
解决办法是:
- 写程序时, 在开头声明 UTF-8 编码:
#coding:utf-8, 告诉操作系统: "不要使用系统默认的编码表, 而是使用 UTF-8 编码表来解码" - 或者, 碰到中文时使用
decode(‘utf-8’)函数来解码成 Unicode 编码 (就如上面强调的, Unicode 记录了字符在各国编码表中的映射关系, 包括 GBK 编码. 解码成 Unicode 之后就可以正常显示 GBK 编码了)
# Python 3
Python 3 的默认编码是 Unicode, 所以不存在乱码问题.
# 4. 认识
- 如果字符都是英文的, 就不存在编码问题
- 如果使用 Python 2, 而且程序中包含非英文字符(比如汉字), 需要注意编码问题
- 如果使用 Python 3, 即使程序中包含非英文字符(比如汉字), 也不需要考虑编码问题, 因为已经自动处理好了
- 开脑洞: 如果技术发展水平很高 -- 存储空间和带宽没有限制, 那么上面这些编码问题都将不复存在. 不过, 现实就是"带着镣铐跳舞" -- 在有限的资源中解决问题